In todays post we want to share with you some tips that will keep your proxycheck account secure. We're doing this because we're seeing an uptick in accounts being taken over by malicious actors and in the volume of accounts we're having to disable for breaking our terms of service.
So without more preamble let’s get into it!
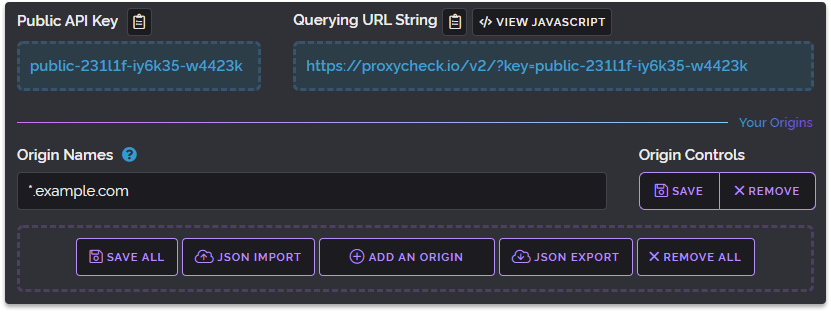
Keeping your API Key secret
This is the first line of defence to keeping your account from being breached. We issue a 24 character long API key to every account where each character has 36 different possibilities which results in 22 undecillion key permutations. This makes our keys practically impossible to brute force.
But this built in security by way of the key length and complexity means nothing if your key is not kept secret. The number one way our accounts get compromised is due to the key being leaked, usually in source code through publicly accessible code repositories and key misuse for instance trying to use your private key in public facing code.
If you work on an open source project that integrates our service you should always make sure the key is being included from a file that isn't included in your main project or loaded from a database so it won't be inadvertently shared within your code repo.
And remember when making queries to our API you can use TLS encryption, since all server-side requests must include your key this is the best way to secure your key from MITM attacks.
Secure your account with a password
When you signup you'll be emailed a link to login to your account and one of the first things you should do is create an account password. This will still allow you to login using your API key but it will require the password in addition to the key. Setting up a password also enables logging in using your email address.
And of course don't reuse a password you use somewhere else because that will open you up to credential reuse attacks should we or another site you log into be compromised. We strongly recommend the use of a password manager which can generate randomised passwords for each website you signup for.
Enable two-factor authentication
In addition to setting a password you can enable two-factor authentication which is essentially an extra password you enter when logging in that changes every 30 seconds making it difficult for an attacker to obtain.
You can use web based two-factor authenticators to generate these passwords but we strongly recommend using a separate physical device like a smartphone to generate them. Many password managers also include two-factor capability and we fully support the industry standard method for these called TOTP (Time-based One-Time Password).
We have chosen not to offer SMS based two-factor support because it's not secure enough. This method of two-factor is vulnerable to social engineering of the phone network staff who may issue an attacker a sim card with your number on it allowing for the attacker to intercept your two-factor codes.
To encourage the setting of a password and the enablement of two-factor authentication we offer customers two extra custom rules in addition to their plans provided rules.
Pay attention to email alerts
Many actions within the Dashboard cause email alerts to be sent and you should pay attention to these, they may give you an early warning that someone other than yourself has gained access to your account.
We send alerts for the following reasons:
- You've logged into the dashboard from a new IP Address
- You've set or changed your account password
- You've enabled or disabled two-factor authentication
- You've changed your email address
- You've signed up for or cancelled a paid plan
- You've generated a new API Key
And of course make sure our emails are reaching your inbox and not being caught in your spam filter.
Keep your email address upto date
If we need to email you for any reason and we're unable to do so your dashboard will show a notification at the top warning you of this. It's very important you then update your email address because we may disable your account if we're unable to contact you.
While it's rare we disable accounts for this reason there have been occasions where we have had to disable accounts to get a customers attention about an important issue with their usage of our service.
Don't use temporary email services
Like we stated above, it's very important we're able to contact you for specific account related issues. Due to temporary email services being as their name implies temporary it means we can't contact you after you signup for our service. It is for this reason we have an item in our terms of service regarding the use of temporary email addresses.
If you're found to be using a temporary email even a long time after you initially signed up the account will be disabled. You will then have one year to contact our support to have the account re-enabled so that you can change the email address. If you don't contact us within that year the account and all associated data is automatically erased.
Something else to note about temporary email services, many of them don't have any kind of account system and the inboxes of their temporary addresses are accessible in a public feed. This can put your account at risk of takeover.
Don't create more than one free account
This is the number one reason that customers lose access to their accounts. And in-fact just this year alone we've had to disable thousands of accounts. We offer a very generous free tier where every feature is available in full and only the quantity of queries, custom rules and the burst tokens you receive are dictated by if you pay and by how much you pay.
But still we face free account abuse. Some users even create hundreds to thousands of free accounts to avoid paying for service and this is something we cannot and do not tolerate. If you're found having more than one free account you're risking all of the accounts you have, they could all be disabled at a moments notice and at any time in the future.
Our stipulations here are very simple, you can have as many paid accounts as you want but the moment you create multiple free accounts you're in breach of our terms of service.
And while we have allowed some customers with multiple free accounts to keep them this is usually because their cumulated queries across all their free accounts remains below 1,000 per day or they've contacted us first to ask permission and provided a reasonable circumstance which we accepted.
But in general we do not allow multiple free accounts and you should always follow our terms of service.
Don't commit financial fraud
Although this is rare we do sometimes face financial fraud where someone purchases service using stolen payment information or they use legitimate payment information and later issue a chargeback through their bank.
Both of these issues cost us and all merchants a lot of money. Many people aren't aware of how financial crime impacts the costs of goods and services that they buy but it does, we have to factor in the cost of payment insurance and the accumulating losses due to chargeback fees and employee time spent collecting and submitting evidence for financial crime investigations.
We take a very hard stance on this, if we suspect you're using fraudulent payment information or you issue a chargeback with your bank we will refund the subscription and disable your account. There are no exceptions to this.
So that's our full guide to keeping your account safe and secure. If you ever need help with your account please don't hesitate to contact our support. Even if your account is disabled you have a full year to contact us to recover any of your data or rectify the circumstance that lead to your account being disabled. Stay safe out there and have a wonderful week.