As the year comes to a close we thought it would be interesting to share with you the story of Raven which is our internal codename for our current inference engine. Currently Raven is at v1.32 and runs all day on every one of our servers and it consists of three parts.
- The training engine which generally takes just under a month to create a new model which is then loaded on all our servers.
- The real-time Raven client which runs on your queries live within only a few milliseconds.
- The post-processing Raven client which runs on STYX our server dedicated to inference.
This is what Raven looks like when we're training a new model. Fair warning, it's not very visually interesting.
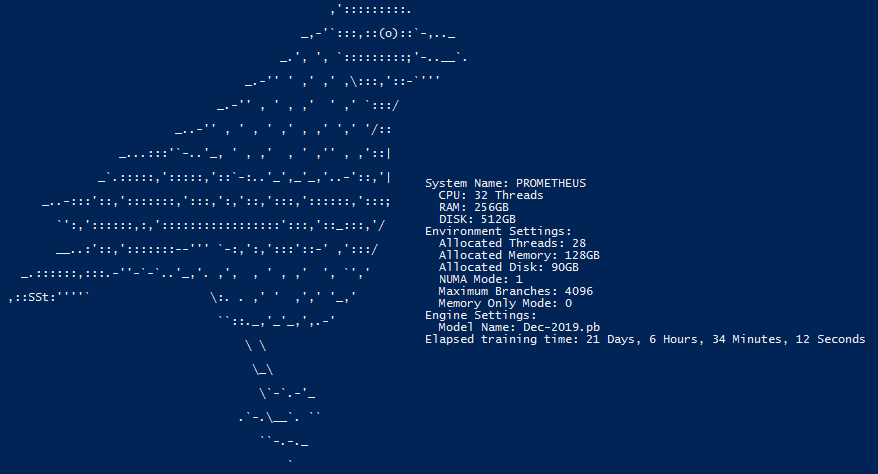
You can see in the above screenshot we started this model in early December and it is yet to complete. We're expecting it to finish around Christmas time. When developing the engine we had to overcome quite a few obstacles. Some of those we overcame by throwing more physical resources at the problem (cores, memory, storage). Others we had to solve with better software.
The first iteration of the Raven client was single threaded and we focused on acquiring servers with very high single thread performance (high IPC and clock speeds). We knew the industry wasn't moving in this direction and instead was building processors with higher core counts instead of increasing instructions per clock.
So after a lot of redevelopment the Raven clients that run on each of our cluster nodes were re-engineered to use multiple threads. We even added support for NUMA (non-uniform memory access) allowing us to efficiency make use of multiple processors in a single system. Our PROMETHEUS node for example is a dual-socket XEON system and it's where we primarily train the Raven engine once a month, it also runs the raven real-time client since this server also acts as one of our main cluster nodes which answers customer queries.
Another issue we've had to overcome is the engines determination throughput. Almost every day we deal with more queries than the day previous as the proxycheck service becomes ever more popular. In-fact it's not uncommon to break our single highest query day records several days in a row. So with all this constantly growing traffic the engine, especially the post-processing engine which is specifically designed to be more thorough needs constant adjustments and refinements to be able to process every address we receive on the same hardware we've allocated to it.
Some of these changes we've shared with you previously such as our bucket system of pre-computing and reusing data about similar addresses so that the engine doesn't have to start from nothing when forming a decision about an address it hasn't seen before.
Other changes to the way the engine thinks and weighs decisions have been made over time as we've learned what matters most when determining if an IP is bad or not. We have been relying a lot more on attack history as a way for the engine to make faster decisions as data that can be read from a database is a lot quicker to use than forming a decision based on weighting lots of abstract data points especially when a single address could have more than a thousand neighbours with varying levels of weighable behaviour.
We've also made a lot of structural changes to the plugins we've developed that our engine uses for evidence gathering. Making them more efficient with process recycling, shared memory pooling for their gathered data, socket reuse and remote socket use through an internal mesh network between our clustered servers and other resource use optimisations. We have in-fact developed an application we call Commander which can dynamically spin up extra resources as the load on our cluster becomes higher allowing us to expend more resources for evidence gathering when necessary.
To speak a little bit more about our evidence gathering, we do often probe addresses that the engine wants more information about. That means we will look for open services running from those addresses including proxy servers, mail servers and web servers. We will allow it to run scans to determine if an address has vulnerable services exposed to the internet. These scans help to provide concrete evidence of bad addresses and you'll find a lot of this data funnelled into our Compromised Server type responses. Other plugins for the engine load the website pages you include in your tags to us so we can categorise the page and assign it an access risk level.
With our constant adjusting of our behind the scenes software stack like Raven and its associated plugins (the Commander spoken about above is less than a year old for instance) it's not always evident that we're working on things, more visible features like the custom rules feature get a lot more show time on the site and our blog here but rest assured we're always improving things behind the scenes.
Over the past several months the service has been at its most stable with the least amount of node drop outs, least connectivity problems and our fastest ever response times. We've also been able to maintain a real-time processing ratio for our post-processing inference engine through constant code improvements without adding more hardware while still increasing the accuracy and thoroughness of the engine.
Looking past Raven we also greatly improved cluster communication. Many of you have noticed that the stats within your dashboard and at our dashboard API endpoints are updating significantly faster (at or under 60 seconds most of the time). This is not a coincidence, significant engineering effort went into redesigning that whole system for your benefit so we could make sure our stats continue to synchronise quickly no matter how much traffic you generate.
We are really looking forward to 2020 where we'll be continuing our refinement of our service in every which way. Thank you for reading this look at Raven and merry christmas!