![]()
Over the past several weeks we've been adjusting the website's appearance and usability. Today, we'd like to share some more changes we've made since our last blog post.
Signed In Devices
A few years ago we added a feature to the bottom of the customer dashboard that allowed you to sign out any devices that were signed into your account. Essentially erasing their sessions server-side so their access to your account can be revoked even if you don't have access to those devices anymore.
We wanted to expand on this feature by actually showing you the devices which are signed into your account, what browser and operating system they're using, the country and region they accessed your account from and the last time they accessed it. To that end, we've added a little blue question mark next to the "Sign out everywhere" button which will show a little pop-up like in the screenshots below illustrating the same view on our dark and light site themes.
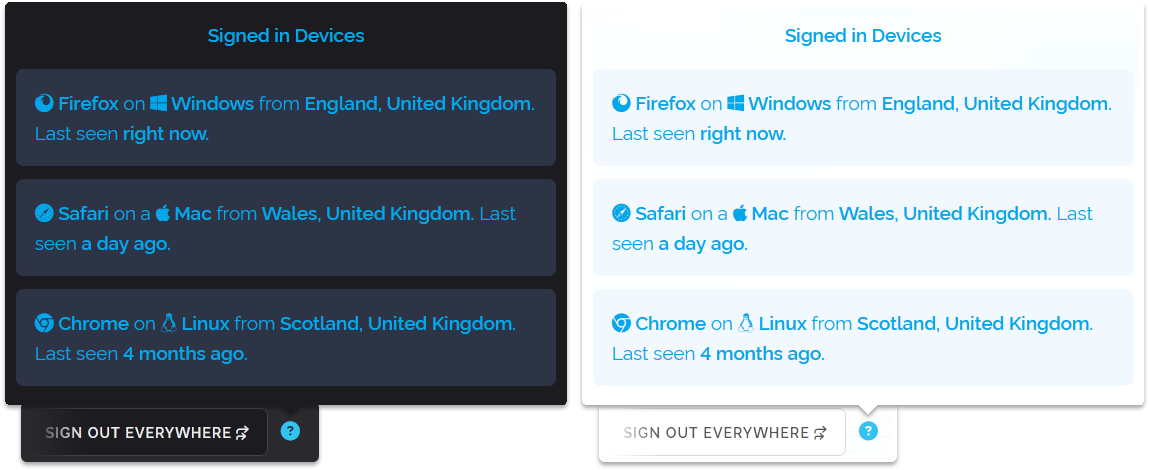
We decided to make this feature ourselves in-house instead of relying on an external service or product. This means we will maintain the list of device characteristics ourselves. To begin with, we're supporting all the major browsers (Firefox, Chrome, Edge, Safari, Opera, Brave, Internet Explorer) and also the major operating systems (macOS, Windows, Linux, Android, iOS, iPadOS, ChromeOS etc). But we've also added some specific detection for particular devices so for example if you're using an iPhone it will just say iPhone instead of iOS. We've also done this for iPad and some other product categories.
This device data is stored server-side with your normal account information and when you clear your signed-in sessions (either one at a time or everything all at once) the data associated with the erased session (browser, os, location, last seen time) will also be erased from our servers at the same time. We're doing it this way because this feature isn't intended for us to track you but for you to track access to your own account.
Confirmation Dialogs
We've had confirmation dialogues for a few important areas of the Dashboard including changing your API key, upgrading or downgrading your paid plan, cancelling a paid plan and erasing your account. We did this to make sure unintended changes weren't made by accident. But customers have told us they would like these confirmation dialogues in more areas specifically when they try to erase a Custom Rule or Custom List.
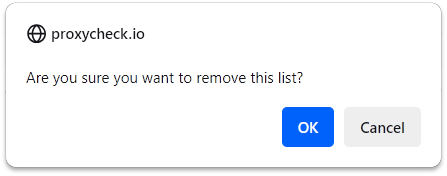
We completely agree and so we've added confirmations to both of those features, when you try to erase a rule or list a modal will appear with a darkened background which asks you to confirm or cancel the removal like in the screenshot below.
Custom Rules API
A feature we've been asked for a few times since we introduced Custom Rules has been a way to interact with your Custom Rules via a Dashboard API like you can with Custom Lists and CORS domains. The reason we've not added this feature is because Custom Rules are very complicated and we feel the user interface within the Dashboard is the best way to create and alter Custom Rules.
However, there are things we can make accessible that do make sense to enable through an API. Viewing which rules you have in your account and whether they're enabled or not, exporting rules the same way you can through the Dashboard interface (for manual editing or later re-import) and toggling rules on or off.
To support these use cases we've added a new Dashboard API endpoint which you can view all the documentation for here. We've also taken the time to update our official PHP library to support this new Custom Rule Dashboard API. You can obtain that from packagist here or by using the relevant composer command within your environment.
So that is all the updates for today, we do have some much bigger things being worked on alongside these more minor interface changes but it will likely be a few months before we're ready to share those with you. Until then we hope you liked todays changes and have a wonderful rest of your week.