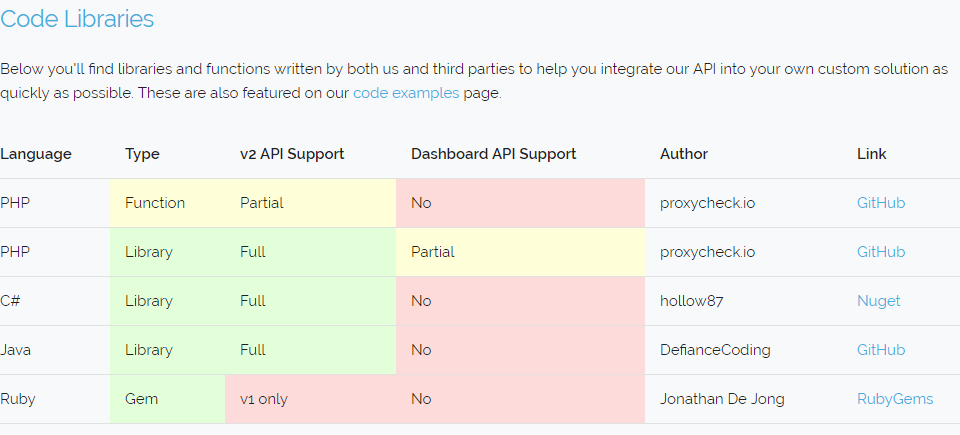
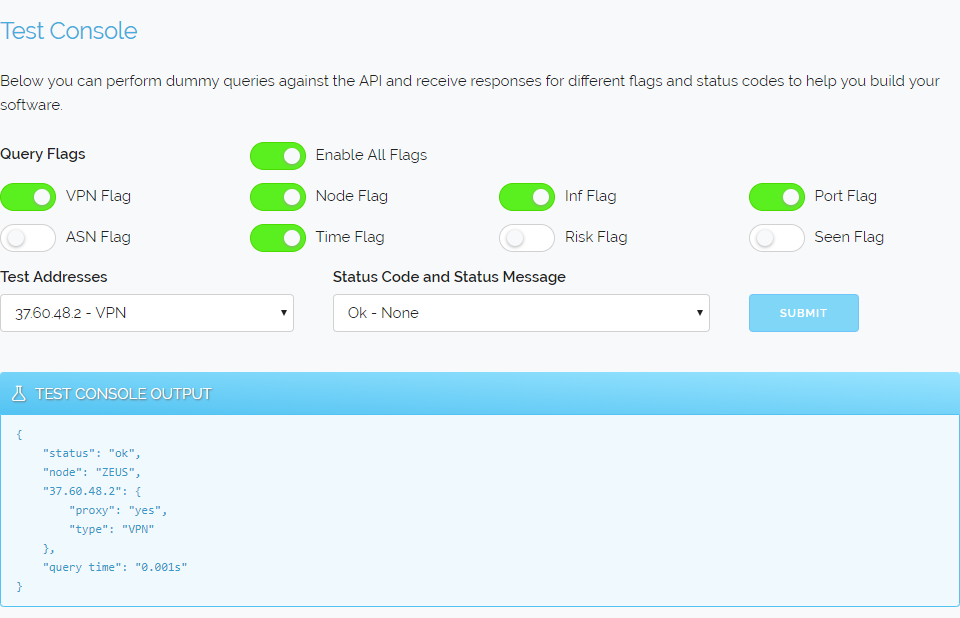
Today is a day I've been looking forward to for a very long time because today I get to share with you all our new custom rule system. This is a new dashboard feature that puts you in complete control of how the API responds to your queries with an unparalleled level of customisation.
This feature has been on our long term roadmap for as long as I can remember. It required lots of planning, experimenting and testing, we wrote the feature several different times from scratch until we nailed it.
We know it's going to be a big deal for our customers because you've been telling us so every month for the past two years. You may not have specifically said the words "I want custom rules!" but you definitely said "Can the API respond this way if x and y happens?". Every month we're asked to add more flags to the API that allow specific use cases.
The two most common requests we receive are. Can you add an easy way to do Country blocking on the API side and what if I only want to block the really bad VPN's and not okay ones? - Well with the new custom rules feature you can accomplish both of these things and a whole lot more.
And that's because not only can you alter the logic of the API but you can overwrite responses with your own ones or create entirely new custom fields containing the strings you specify.
So that's enough talking, let's show it to you. Below is an animation showing the global controls for your rules. The extra control buttons you need only appear when you have rules created and they disappear when you don't. We feel this makes the interface more approachable, less intimidating.

When clicking on the add a rule button a new rule will be added to the page. Below we've added a rule and expanded it to reveal all the configurable options. We've also populated it with three conditions and a single output modifier. Each rule you create can have as many conditions and output modifiers as you like. And we also allow you to specify multiple values for a single condition, more on that in a bit.
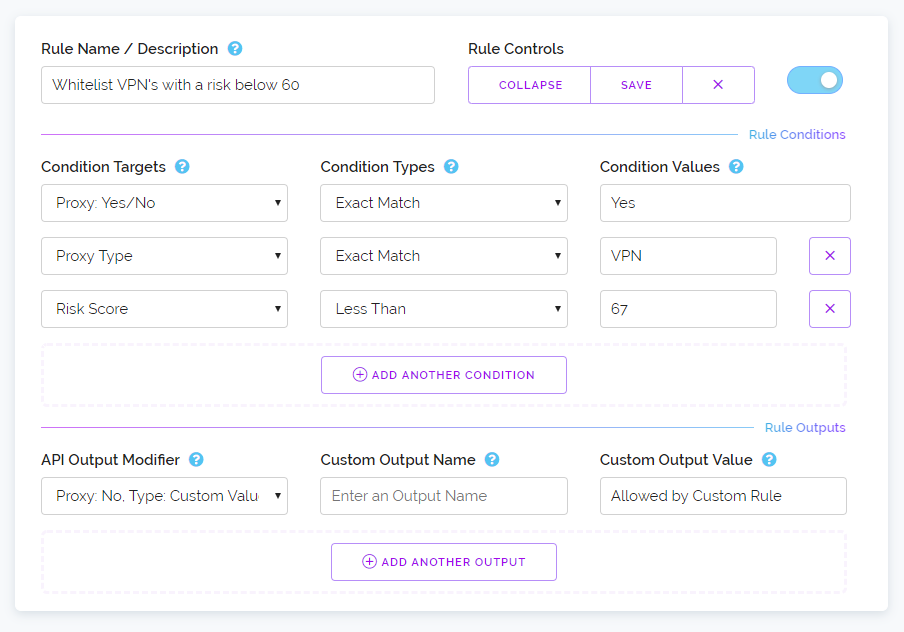
In the screenshot above hopefully you can identify what this rule will accomplish just by looking at it. But essentially if you send an IP to be tested and it's a VPN but its risk score is below 67 then with this rule enabled the API will output Proxy: No. Normally in this situation it would output Proxy: Yes.
Which means this rule has enabled you to only block VPN's which we consider dangerous by utilising our risk score. Now you could create logic like this in your own client software that talks to our API. But most of our customers are not computer programmers and are instead utilising plugins and client software which may not take advantage of all our API responses or the developer of their software may have locked-in how the software reacts to most API responses and that may not suit your particular use case.
By moving this logic to the API side with custom rules it enables you to use even the most basic clients available that support our API and still make full use of all current and future features.
The UI we've designed for custom rules goes beyond just looking nice. It's highly functional with instant feedback letting you know if a condition or output modifier you've entered won't work. It can automatically disable rules if the rule isn't valid and let you know which part of a rule needs to be changed before it can be enabled.
We've also made it so you can drag and drop rules around enabling you to adjust the order in which rules are acted upon without the need to erase a rule just because it's in the wrong position.
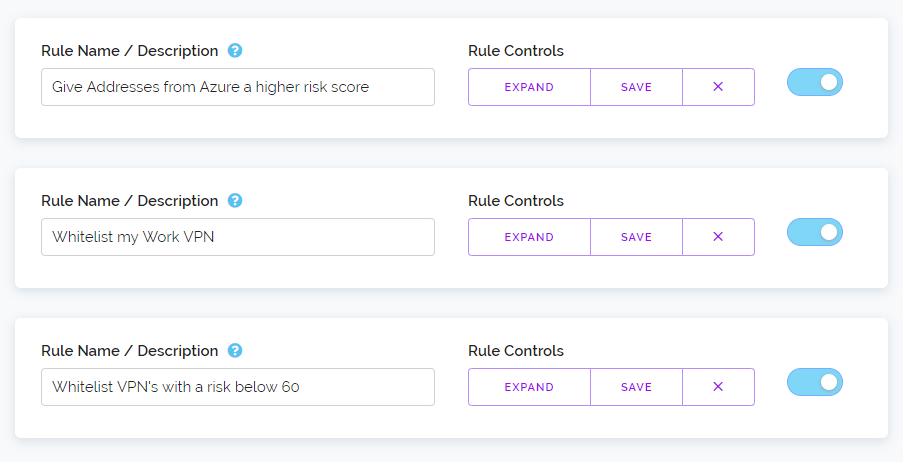
Now you're probably thinking, great now the Whitelist and Blacklist features are going away. Well don't worry, that's not happening. We love those features and it makes it really easy for customers to do simple actions based on IP Addresses, IP Ranges and AS numbers. And in-fact the new rule system works fully in conjunction with those features, you can even make rules based on the result of those lists.
So this all sounds great right - but what does it cost! - I hear you saying. Well we're not charging extra for rules. Instead we're giving you a quantity of rules based on your current plan sizes. Customers on our free plan can enable three rules while our starter paid plan of $1.99 can enable six rules. Each plan can enable an additional three rules over the previous plan.
And to be clear, we're saying enable because all accounts regardless of plan size can create an unlimited amount of rules. You just can't enable more than your plan size allows. So you can create a lot of different rules for testing and see what works for you by toggling different rules on and off without needing to delete one rule to create another.
Each rule you create can have an unlimited amount of conditions and output modifiers and as I mentioned previously you can provide multiple values for each condition within a single rule, this is done by separating them by a comma. This means if you wanted to create a rule that applied to 20 different countries you could do that by simply listing 20 countries as a single value in a single condition. You do not need to create 20 different conditions or 20 different rules to accomplish that.
So that is the new custom rules feature. It's live right now for all customers within the dashboard and we would love to hear your feedback. The last thing to mention is this feature only works on our v2 API so if you've not made the switch from the v1 API now is the perfect time to do so!
Thanks for reading and have a great week.