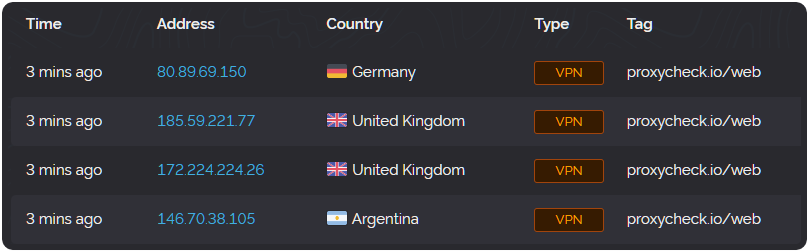
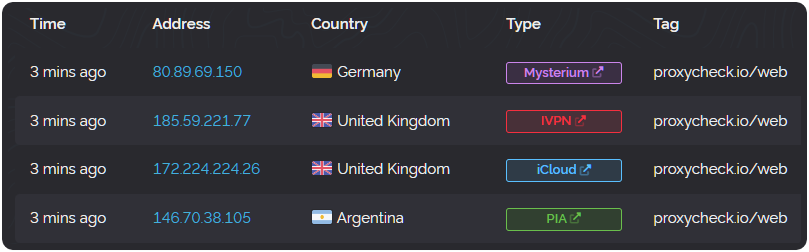
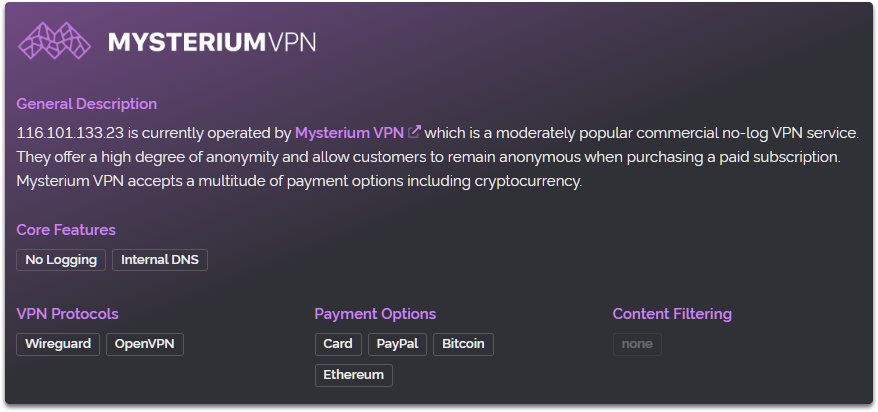
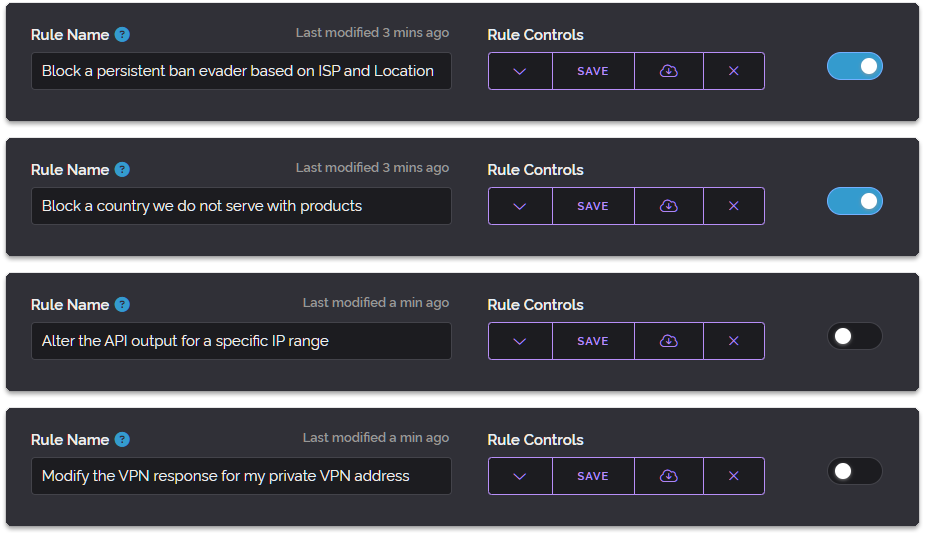
In computing, there is a strong resistance to complete rewrites and there are many great reasons for that including cost, time, the potential for new bugs and regressions in functionality.
Instead, the software industry prefers to do what we call refactoring where you take existing code and improve it by making many small changes over a long period so that each change can be more easily implemented and the results of those changes measured in a controlled manner. In short, it's fast, it's cheap, it gets results and it lowers the potential for problems.
But now and then it may be required to completely rearchitect a system and there can be many reasons. You need more performance, you need the code to scale better to more computing resources, new hardware has arrived that runs the old code poorly or not at all, new libraries, operating systems or execution environments are incompatible with your old code etc
And so many of the above conditions can precipitate a rewrite.

This is exactly where we found ourselves this year with some of our backend software written since 2017. This was software that was designed for a specific operating system (Windows Server) which meant we had leveraged some Microsoft-specific operating system functions which made our code incompatible with Linux.
We had also designed this software around certain hardware that we had access to at the time which meant low core count processors and slow storage using hard disk drives. This resulted in a lot of our backend systems being conservative in how they used the hardware, meaning mostly single-threaded operations and serial data access.
Our current servers average 23.5 CPU threads whereas when most of the code we're discussing was created our biggest and best server only had 8 CPU threads. And when it comes to storage we used to use HDDs that could manage only 800 IOP's now we're dealing with NVMe SSDs that can handle 1.2 Million IOP's.
With us wanting to rewrite things to be processor-independent and operating system agnostic whilst taking better advantage of our latest (and future) hardware it necessitated some rewrites. For sure we could refactor some of our old code and in many smaller cases that is what we did but for the biggest stuff rewrites were the right way to go.
So how do you re-architecture your software the right way?
Firstly you need to do a full code review for the system you're going to rewrite. This includes reading all of the code and understanding and documenting all the tasks the code performs and why it does them. This is paramount because otherwise, you will forget to include functionality in the new rewrite that the previous iteration contained.
Secondly, you want to identify all the deficient parts of the code that you want to improve upon. This could be simply messy or unmanageable code or it could be just unproductive code that performs poorly or doesn't meet your goals for now or the future (such as tying you to a particular operating system).
Thirdly you want to plan how you intend to improve the code to meet the goals you have for the new program. For us that mostly entailed making things multithreaded, better use of our storage system's I/O capabilities, not using any Windows operating system-specific features or functions that won't be available on Linux. And of course, the culmination of all this work is added scalability and flexibility.
Fourth and finally you write and test the code. We did a lot of testing during development to test our many hypotheses and this informed our design process. As we learned the capability of certain approaches to problems the decisions we were making changed along the way.
So let us go over some of these.
1: About two years ago Microsoft ended support for WinCache which was an in-memory data store for PHP. We made extensive use of this and so we had to build a replacement. Thus two years ago we wrote what we call ramcache. It performed the same role and re-implemented all of the WinCache functions. We were also able to extend the functionality. WinCache had a 85MB memory limit, we have no such limit in our ramcache as one example. We also made it operating system agnostic aka it will run on anything including Linux.
2: Webhooks. We use a lot of webhooks, mainly for payment-related events such as sending you an email when a payment is declined or coming up but we also use webhooks for what we consider time-critical events such as when you make a change in your Dashboard that must be propagated to all cluster nodes very quickly.
3: Our database synchronisation system. At one time the processor usage caused by synchronising our databases was as high as 70%. This did scale back as a percentage when we upgraded to systems with faster processors but it was still very high and we saw the usage steadily increasing as our customers generated more data per minute. In this case, we developed a new process called Dispatcher to handle this traffic and we dramatically reduced processor usage to just 0.1%.
4: Cluster management, node health monitoring & node deployment. Before our rewrite, this heavily relied on Microsoft-specific operating system features, especially the node health monitoring and node deployment features. We've now rewritten all of these to also be operating system agnostic and processor independent.
So let's look at some net results. Previously our webhooks (where one server specifically sends out a small update to one or more servers in the cluster) took an average of 6 seconds for a full cluster-wide update. The new code which is multithreaded when it comes to network usage has reduced this time to just 0.3 seconds. That's a 20x performance improvement.

When it comes to Dispatcher, this was a ginormous change for us as everything that keeps our servers in sync with one another utilised our previous system. The old system was so encompassing it didn't even have a name because it wasn't thought of as one specific object, the code was interspersed with so many other functions and features that it was almost omnipresent throughout our code.
This has all changed with Dispatcher which provides a standardised interface for reading and writing to our databases and it provides a framework for our cluster nodes to provide data in the most passive (and thus least resource-intensive) way possible through the use of packaging up node updates and having a singular chosen master node for each geographical region temporarily selected as a collector, processor and distributor of database updates.
You can think of Dispatcher a lot like a train network. Each node operates its own train that is constantly going around the track to all the other nodes and picking up data. Master nodes pick up data from non-Masters, they process the data and then carefully decide where in the database that data should be inserted. It is then repackaged by the Master and presented to any trains that come by from non-Masters which pick up those updates.

Every few minutes the nodes hold a vote and the node with the most free resources and best uptime is chosen to act as the master for that geographical region. The way we stop conflicts from having multiple master nodes able to distribute updates simultaneously is by having clearly defined containers, merge conflict resolution and a database that is built around a structured 1-minute time table.
Each minute in the real world is accounted for in the database with a master node attached to it for that specific minute and geographical region. That node and only that node can perform maintenance and alterations unless the nodes agree to remove it from that minute and assign another node, thus allowing another node to become the master over that minute. Any node can read from a minute but only masters can perform alterations and writes.
What all this results in is a high-performance database synchronisation system that scales to however many server nodes we have and most importantly with the least amount of processor and storage burden.
While performing all these code rewrites and refactors we also investigated new technologies and tuned our execution environments for the code we author. To that end, we upgraded to the latest PHP v8.2.6 across our entire service including all our webpages. During this upgrade process, we also engaged the latest JIT compiler present since PHP v8 as we saw massive improvements in page load times across the site with no regressions.
So that's the update for today, we hope you enjoyed this look at what we've been up to and the illustrations.
Thanks for reading and have a wonderful week.