![]()
Today we're introducing a new feature called device estimates which presents you with the estimated device count for specific addresses and their subnets based on actual data derived from the usage of our API by customers when supplying the &asn=1 flag with your requests.
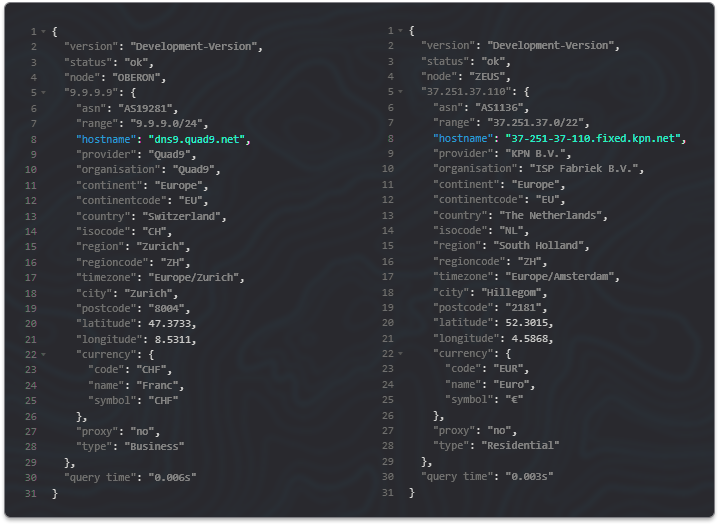
By using these new data fields within the API (shown below) you'll be able to make decisions about whether to allow an IP to interact with your service based on how many devices are estimated to be active behind it which allows you to make a better risk assessment.
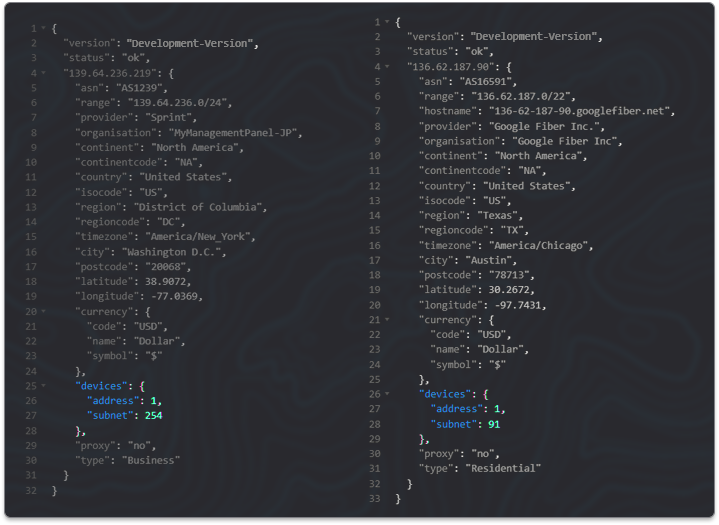
One thing we were very keen to maintain with this feature is user privacy. This is why we do not detail the exact devices being used behind an IP address and in fact we don't perform any kind of device fingerprinting as all of this data is gathered anonymously and our estimated number is based on number theory and not specific device tracking. This means we can still maintain accurate device estimates without impinging on user privacy.
The new device estimate feature is available now in the API, we've issued a new version dated the 19th of November 2024. This data is also exposed within the Custom Rule feature which means you can now build rules against device counts for both singular addresses and their subnets. We've also added device estimates to our individual threat pages.
In addition to presenting this data in the API we're also using it internally to help us discover previously undiscovered VPN services and proxy servers, we'll do another blog post on the results of this in the future.
That's the update for today we hope you'll take advantage of the new feature and thanks for reading!