
Today we'd like to take a deep dive into our European infrastructure as we feel it'll make for an interesting blog post. If you're not looking for a long and technical analysis it's safe to skip this post as we're not announcing any new or changed features below, we're just detailing hardware today.
Why are we doing a deep dive?
Firstly the reason we're doing this is because we have moved our entire European cluster to brand new hardware. This has been something we've been attempting to do gradually since 2020 by purchasing more powerful hardware and slowly phasing out older machines.
But we reached a point where this strategy wasn't giving us enough of a capacity jump. When you grow a cluster without infinite money you usually choose to grow either high or wide. Meaning add only a few servers but have them be very performative or add many servers and have them be low to medium performing.
Naturally these decisions result in compromises. You need to factor in redundancy against hardware failure (having many nodes), performance (faster CPU's, more memory, faster storage etc) and cost ($$$).
We felt that we could compromise on the amount of nodes to vastly increase the performance of each node, so prior to today we had 6 live nodes and 1 hot-spare node for Europe. We decided to reduce this to 4 live nodes and 1 hot-spare and use the money saved from consolidating to drastically raise performance. Now the new upgrade we're about to reveal is still several times the cost of our previous infrastructure but the performance gains are much higher than the cost increase.
Put simply our cost per request falls dramatically when comparing total request capacity of our new servers vs our old servers. So without speaking more abstractly let's get to the technical details. Let's list what our servers were before and what are we operating now.
Our previous European infrastructure
For Europe our prior servers mostly consisted of Haswell era Core i7 Quad Core and XEON E3 Quad Core processor based systems. Only our newest node (THEA) operated with an 8 Core EPYC processor. Most of these servers were equipped with 32 GB of memory and exclusively used Hard Disk Drives except for THEA which used NVMe based flash storage.
We've created the graphic below to illustrate our prior hardware.
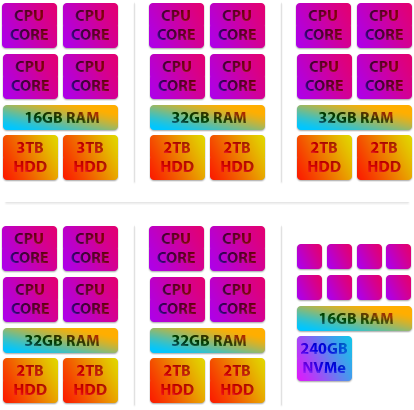
As you can see the majority of our live infrastructure were quad cores and using hard disk drives. You may be wondering why we choose to own our hardware at all as opposed to using Amazon Web Services, Google Cloud or Microsoft Azure and there are a few good reasons.
Why not Cloud hosting?
Firstly, those cloud services cost a lot of money relative to the market. And while you can scale quickly to support lots of customers you can often be blindsided by sudden increases in costs whether from database transactions, egress fees, compute or storage use etc - We estimated the cost of using these common cloud providers to be several times higher than operating our own equipment.
Secondly, those services do have outages and in multiple instances we've seen worldwide outages of both AWS and Azure. This means if we were to use these cloud providers we would need to use more than one simultaneously which complicates our software development and compounds the cost problem as we need multiple nodes running simultaneously at each cloud provider for redundancy.
Thirdly, performance. It may sound counterintuitive that these mega cloud providers don't offer the best performance when you can scale your application to hundreds or even thousands of servers. But when you're dealing with billions of requests each with a request payload under 1000 bytes the TTFB (Time to First Byte) matters. This problem is mainly due to their servers using either XEON or EPYC server grade microprocessors which feature low single-thread performance by design to allow for very high core counts in an acceptable power envelope.
One of the main reasons that we previously chose to use Core i7 and E3 XEON's is because they all have very high clock speeds and thus single-threaded performance when compared to lower clocked processors of the same architecture. It's not uncommon to receive a 2GHz E5, E7, Silver or Gold server grade XEON CPU when using one of these cloud providers where as the consumer Core i7 and workstation E3 XEON processors are regularly in the 3.5 to 4.1GHz range. This high single thread performance is important to maintain each individual requests low latency as multiple CPU threads do not work together on a single API request in our architecture.
Forth, security. One thing all these cloud providers have in common is the instances they provide are virtualised. And as we've seen over the past several years with Spectre and Meltdown the types of vulnerabilities being found make being on the same server as other individuals risky. There is always the possibility that the virtual machine host becomes compromised and the ability to read the memory of another virtual machine guest can occur.
These types of exploits aren't just theoretical anymore, real attacks like this are occurring every day on unpatched systems and as new vulnerabilities are discovered they can be exploited before mitigations become available. And while newer processors such as AMD's EPYC line now offer fully encrypted virtual machine memory as default with in-CPU hardware based cryptographic stores there's still always the possibility for vulnerabilities that undermine these added layers of security.
This has been a very strong reason for us to use dedicated hardware whenever we can as if we're the only user on the system it fully eliminates the possibility of this issue affecting our infrastructure.
Our new European infrastructure
So what exactly is the new hardware we've chosen for our European cluster? First let's show a graphic and then we'll go into more detail.
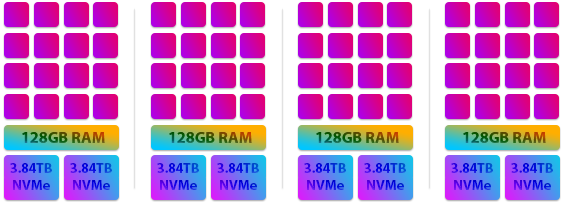
Because the new servers have so many cores we've had to make them a little smaller in the above illustration but rest assured each core here is 1x to 2x higher performing than the cores in our previous machines and as you can see there is 16 of them per server as opposed to 4 or 8 in our previous cluster.
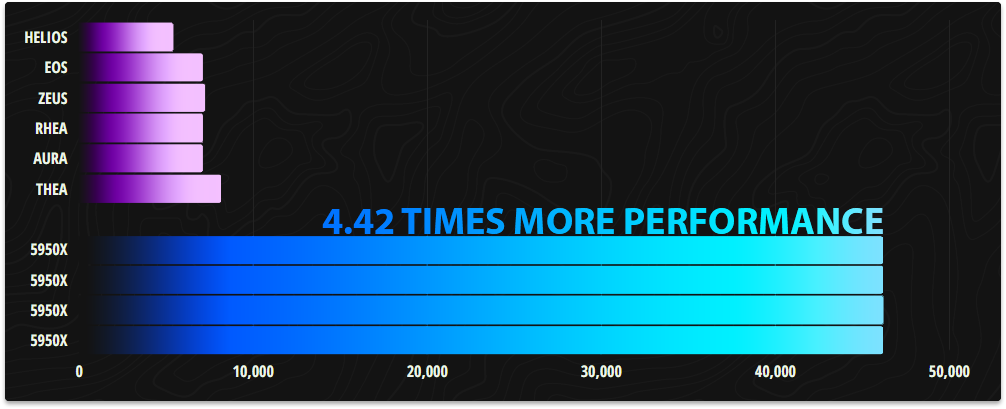
Based on the CPU benchmarks we've performed these new servers raise performance by 4.42 times what we had before and yes you read that correctly. We would need to duplicate our old infrastructure just under 4.5 times to be the equivalent in CPU performance to our new infrastructure. That would be 24 of our old servers to match 4 of these new ones.
And that is because we're using the AMD Ryzen 9 5950X 16 Core / 32 Thread Zen 3 based microprocessor in all of our new servers. This is the fastest processor AMD sells when it comes to single-threaded performance and the fastest they sell up-to 16 cores in multithreaded performance. It has a base clock of 3.4GHz and a boost clock of 4.9GHz. And in our testing these CPU's stay at a steady 4.7GHz.

In CPU passmark our previous infrastructure with all servers combined under a multithreaded test scored 41,772 points. Our new infrastructure by comparison scores 184,652 points.
And this processor doesn't just bring the heat when it comes to performance as it also supports upto 128 GB of the fastest ECC memory. Which just so happens to be exactly what we've equipped it with as we're using 3200 MHz ECC 32 GB modules from Samsung which are the fastest JEDEC compliant ECC modules available.
As if that wasn't enough this processor also supports PCIe 4.0 which means we were able to equip each server with two 3.84TB PCIe 4.0 NVMe Enterprise drives from Samsung with a rated sequential transfer speed of 7,000MB/s and over a million IOPS. And yes we do have two of these in every server.

One of the things we've tried to do with our previous infrastructure is not allow for our hard drives to hold us back. In that endeavour we developed a tiered caching system for database reads and writes which allowed the API to run consistently fast even while serving a huge volume of unique data for every request. And while we will continue to use this system even on our new servers we now have raised the base level of disk performance by 7,000% when it comes to sequential access and 34,000% for IOPS.
Put simply this performance gain will have a dramatic effect for smoothing data access which will result in a more consistent experience for our customers accessing the API.
The numbers when you combine all our new hardware together is mind boggling. 64 Cores, 128 Threads, Half a terabyte of memory and 32TB's of the fastest NVMe based flash storage you can get. And one quick note about the storage, with this change to flash based storage for our European servers we have now eliminated all hard disk drives across all our infrastructure which includes our North American servers which have been using Flash based storage since their original deployments.
Why make this move now?
So you've seen the hardware but you may be asking why did we choose to do this now and not earlier. Well a few things aligned to drive this decision.
Firstly we've been wanting to move off our old hardware for a while due to the increase in demand for our services. We estimated that to keep up with demand in only Europe we would need to bring online a new server every 3 to 4 months. One of the things people may not consider when adding servers to a cluster is the more servers you have the smaller the impact adding one extra server has.
For instance moving from 6 servers to 7 servers only redistributes the load between them from 16.66% to 14.28%. The question at that point is will you really feel that 2.38% redistribution on each of your servers? in our experience, not really. But if you're moving from 2 to 3 servers or 4 to 5 the difference is much greater.
So in this situation we decided to grow our infrastructure higher instead of wider by reducing the number of nodes in the cluster from 6 to 4 while making each individual node as powerful as our entire previous cluster. And when we do eventually add a 5th node it will have a larger impact. We think staying around 6 nodes per region maximum is a good standard for us at the moment and as newer and faster hardware becomes available (32 core CPU's with high frequencies for instance) we may just upgrade to those as opposed to adding more servers to the cluster.
Secondly we've seen the DDoS attacks on our service increase in both severity and frequency. And although we use an Anti-DDoS service (CloudFlare). Their ability to scrub all of this attack traffic is limited because we're operating an API and not a normal website that they can just cache and re-serve to our legitimate visitors. This really necessitated us scaling up to be able to withstand these large attacks we've been receiving.
Thirdly the price of maintaining our old infrastructure was starting to become uncomfortable relative to their performance. Right now Europe is suffering through an energy crisis and our older servers offered a very low performance per watt metric when compared with newer hardware. Put simply for every watt of energy they consumed we received around 0.23 to 0.25 units of performance relative to our new hardware which delivers 1 unit of performance per watt, just over a 4 fold increase.
Forth the hardware available in the market caught up to what we wanted. When moving infrastructure like this it's a big job. There's a lot to consider like what hardware to choose, comparing benchmarks, features and upfront cost aswell as long term costs. In addition to that just deploying and setting up all of these new servers in a controlled manner with zero downtime takes considerable time and effort.
So when we decided to change servers we didn't want to do it for just 0.5-1.5x performance gains. That isn't enough of a jump to warrant all that time and effort. But a much larger 4.42x jump? well that's substantial enough to make it worthwhile. When choosing the Ryzen 9 5950X we also considered the R5 3600, R7 3700X, R9 3900, EPYC 7502P and even the Intel Core i7 8700, Core i9 9900K and Core i9 12900K.
Ultimately we decided on the Ryzen 9 5950X out of the AMD processors because it's built on their latest Zen 3 architecture which delivers incredible single thread performance while still boasting 16 cores and 32 threads. When it came to Intels offerings only the 12900K could rival the 5950X in single threaded performance but its microarchitecture with big.LITTLE core structure was unappealing to us and does let it down in multithreaded workloads. It also doesn't support ECC memory.
It took the market quite a while to deliver processors at the level we just discussed. From about 2007 to 2017 quad core processors reigned supreme in the mainstream of the market and most affordable server hosts were only deploying those which is why we ended up with so many of them in our infrastructure. Since 2017 though we've seen a steady increase in core counts with AMD offering 16 cores on their mainstream desktop platform and 128 cores on their dual-socket server platform.
As we mentioned a couple of times above it's great having many cores but single threaded performance still matters which is why we continue to use these more consumer orientated microprocessors which offer much higher frequencies than their server equivalents. It just so happens with the 5950X we didn't need to sacrifice desirable features common to servers such as high core counts (16 Cores) fast I/O (PCIe 4.0) large quantities of RAM (128GB) and ECC (error correcting) memory support.
The last thing we wanted to discuss is redundancy. As we mentioned before when moving from 6 to 4 servers for Europe we considered the redundancy and decided it was a worthwhile compromise. Part of that rationale is because we're not placing all four servers in one datacenter. They have been placed in three geographically separated datacenters across multiple countries.
Conclusion
So that's our infrastructure deep dive for Europe. This is all part of a wider infrastructure plan as we still seek to find good hosting opportunities in Asia. We've tested a few servers last year in Asia and while none of them were able to deliver to our high standards we continue to look and be optimistic we will find something within our budget that has the performance and reliability we require.
Thanks for reading, we hope this was interesting and have a wonderful week.