If you've been using the dashboard recently you may have noticed a few enhancements we've made to it. Including new preference toggles, new API setting options, enhanced whitelist-blacklist displays, a copy API key button and a new action result status indicator along the bottom of the screen.
We've made these changes to make the dashboard both look nicer and present to you more information so you know when a change you've made has been performed successfully.
Below is a screenshot showing the new preference toggles which replace our old tick-boxes.

The new toggles aren't just a visual improvement as you may notice we removed the "Save Preferences" button which means we now save your preferences as soon as you alter one of the toggles.
Below is a screenshot showing our new API Settings pane which is completely new.

The reason we added the first "Main API" toggle is because sometimes users get themselves locked out of their own website due to a misconfiguration of their client-side proxy checker code and this is simply a fast way to deny all checks made with your API Key so you can regain access to your property. This was added based on user feedback.
The second toggle is for security. Sometimes you may use your API Key in a less than secure place or implementation, for example in shipping software to your customers (which we do not recommend). But if you do want to use your key that way we don't want to stop you and so we've added this toggle so you can deactivate external dashboard access through our dashboard API's. What this means is, people cannot alter your white/black lists or view your account usage statistics by only knowing your API Key.
We've also added these new toggles to our refresh of the Web Interface page where we've changed the layout, moved the options to the far right and added a few more toggles for last-seen date and proxy type. As seen in the screenshot below.

Below is a screenshot showing our new Whitelist/Blacklist UI within the dashboard.

With the enhanced White/Blacklist UI you now receive three boxes along the top which display exactly how many IP Addresses, Ranges and ASN's were lifted from the text field below them. This is a great way for you to see if any entry you just added hasn't been detected.
Below is a screenshot showing our new action result status indicator.

You'll receive an indication like this whenever you change a preference, setting or whitelist/blacklist. And these indicators are not just visual, the blue successful indicator only appears if the request was actually performed successfully. You'll receive a red indicator like below if something went wrong.

To see all of these changes and some other subtle ones like the new help indicator icons and API copy button head on over to the customer dashboard. As always these changes are available to all customers whether you're on a free or paid plan.
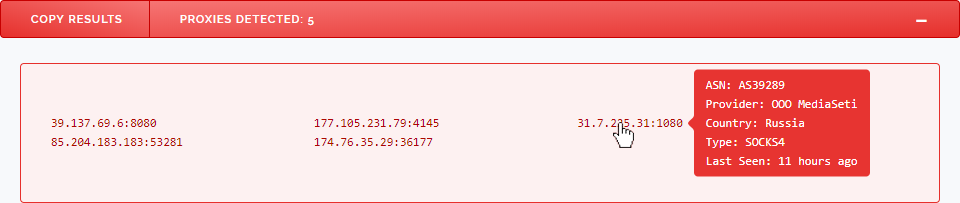

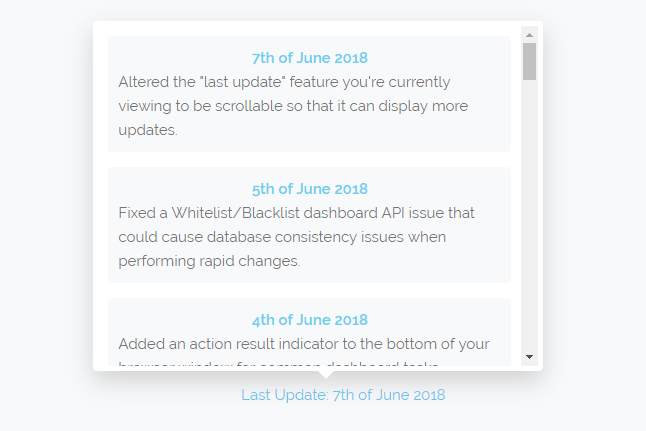 Above is a screenshot showing the Dashboard's last update window which now displays 23 updates going back to October last year.
Above is a screenshot showing the Dashboard's last update window which now displays 23 updates going back to October last year.