![]()
Over the past several months we've been focusing heavily on residential proxy services. The kind of service where you pay a subscription to proxy your traffic through mainly wired residential and wireless 4G/5G internet connected devices.
The reason we've placed such a focus on these services is because of their growing prevelance, the days of free and abused proxies being the predominent type of proxy on the internet is long gone and now paid services that offer access to millions of consumer devices have taken over.
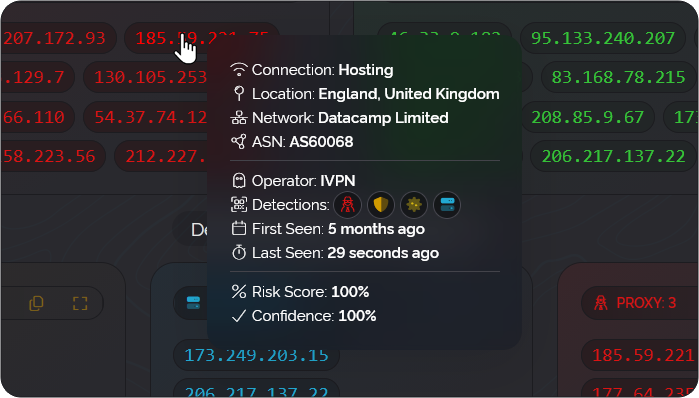
But these do present a problem for a service like our own because unlike the free proxies these don't require port-forwarding and the paid services never provide a raw IP address for you to connect through directly. Instead the addresses are masked behind gateways that are controlled by the paid service and they forward your traffic to a randomly selected IP address within their fleet of devices.
Due to this it's not uncommon to be given an IP address which is shared by many customers of the same internet service provider via technologies like CG-NAT or the address stops acting as a proxy server very quickly when it belongs to an internet service providers dynamic address pool with short lease times.
So we've been trying to tackle this issue, the main way we've gone about it is by massively increasing the number of services we access to obtain the addresses of their entire fleet while simultaneously reducing the time we list each individual address for. This has had the benefit of reducing false positives while maintaining a decent detection rate of addresses that are still acting as proxy servers.
But it hasn't been as good as we would have liked. For every hour that we reduce the time we list an IP we're giving up literally thousands of working proxies that should still remain detected. So to tackle this problem with more nuance we've added a new rules-based system to our address collector which will increase or decrease the timeframe that we list an IP based on several factors including:
- How many times we've used the IP successfully as a proxy server.
- How long its been since we first used the IP successfully as a proxy server.
- How recently we used the IP as a proxy server prior to the latest detection.
- How many unique sources provided us the same IP address.
- Specific weights for specific proxy operators as some use more dynamic addresses than others.
- Specific weights for specific internet service providers as some use CG-NAT or have very dynamic address pools.
- Specific weights for different line types (Residential, Wireless, Business, Hosting etc).
This new rule based system doesn't just apply to residential proxy services with known operators, it also applies to our VPN detection and all other kinds of positive determinations that we're performing. This system is highly variable and may increase the time we display an address by as little as 0.5% or by as much as 1,000%.
The point of the system is to allow us to still expire addresses that we've only seen once or rarely very quickly while making sure that the most abused addresses don't get delisted too early.
As we mentioned above while reducing the time we display an address helped prevent false positives there have been occasions where we've seen some addresses that have clearly been abused as proxy servers for a long time (more than a month continually) get delisted early merely because we weren't given them by a residential proxy service frequently enough for them to remain listed.
In one case we had listed and then delisted an address more than 30 times leaving many hour-long gaps in its detection due to the infrequency that we were given the address combined with how soon we were delisting it. With the new system this wouldn't happen and this address in our simulations would have remained listed for the entire time period that it was being abused.
This change is live right now for all our v1, v2 and v3 API versions as this is a backend change to the amount of time we store and display positive detections and not an API specific logic change. We launched this change today after extensive testing and our hope is it will allow us to further reduce default listing times once enough data has been built up for the rules to work effectively.
Thanks for reading and have a wonderful week!